NeurIPS2020
Social Learning
Created: Feb 9, 2021 9:36 AM
Social Learning / Social Cognition
- Learning from other agents
- Not same as multi-agent learning :
- Multi-Agent Learning: Learning collaborating/coordinating with other agents to solve a particular problem
- Relevant concepts in social cognition:
- Theory of Mind : Generally modeled as $<Beliefs,Desires,Intention>$
- Coordination
Learning Social Learning
Kamal Ndousse, Douglas Eck, Sergey Levine, Natasha Jacques
Main Contributions
- Analysis of why social learning doesn't work so well in model-free agent
- Introduction of a novel model-based auxiliary loss which helps agent manifest social learning and learns by observing the actions of the 'expert' agents present in the environment
- A new environment that promotes social learning
- Zero-shot transfer results showing agents that use social learning generalize better to new environments
Precursor
- Imitation Learning (Behavior Cloning, etc.) : Can break if the agent encounters trajectories which were not present in the training data
- Inverse Reinforcement Learning : Reverse engineering reward function by observing actions of other agents
- Other attempts at social learning: In most of the approaches, the learning agent has access to the internal dynamics of the expert agent
NOTE : This work focuses mainly on Multi-Agent POMDP
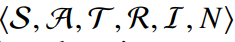
- $\mathcal{I}$ - Function that maps environment state to individual state
Why is social learning difficult?
- Sparse rewards
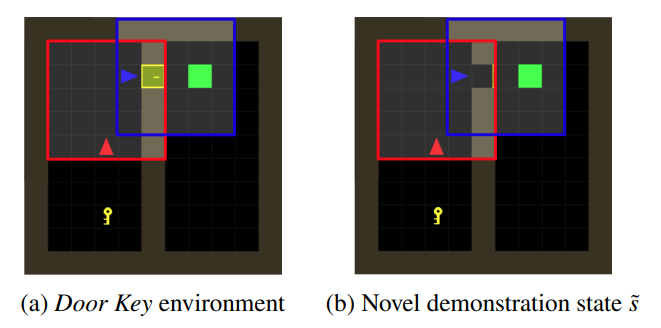
- $\tilde{s}$ is the demonstration state. Difficult to reach through random exploration
- For eg. if the novice agent uses policy gradient based learning
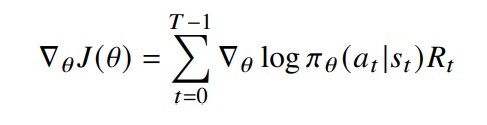
- No reward received by the novice agent when $\tilde{s}$ is reached ⇒ $\mathcal{R_t}$ = 0 ⇒ no update
- All Q - values become zero in case of Q learning
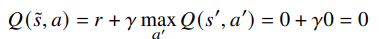
- Access to the expert agents policy?
Method
- Introducing a model based reward in addition to the model-free reward
- Motivation: The problem can be solved if the novice agent has access to the expert agent's policy
- The expert agent's policy is a part of the state transition function $\mathcal{T}(s_t, a^N, a^E)$
- Mean absolute Error (MAE)
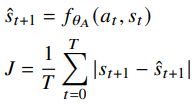
- Approach is called SociAPL (Auxiliary predictive loss)
- Important advantage over other similar methods: The experts can exist in the environment minding their own business and the novice will still learn
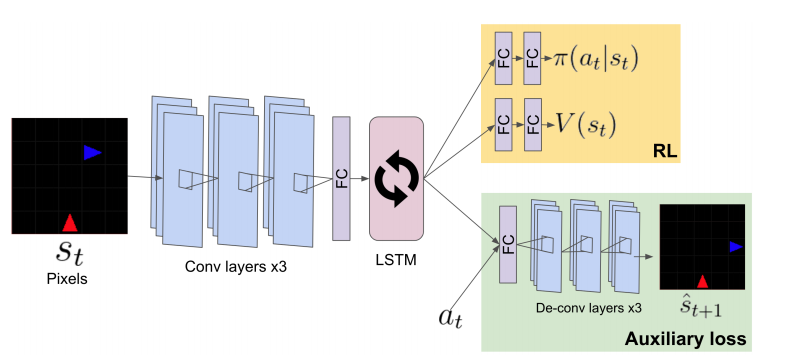
- Example

Social Learning Environment
- Individual exploration is harder than social learning
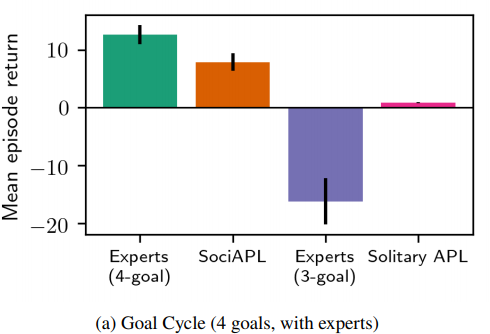
Goal Cycle
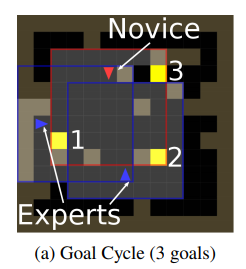
- 3 goal tiles where the agent will get a positive reward
- Traverse the three goal tiles in a specific order
- Penalty on deviating from the order
- Color of the agent changes as it collects more rewards: Blue → Expert, Red → Novice. Color resets to red on incurring a penalty
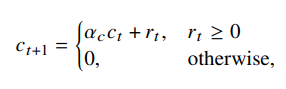
- $c$ - Prestige. This rule helps induce prestige cue into the agent
- Experts are trained using a curriculum since individual exploration is difficult
Performance
- In the goal cycle environment
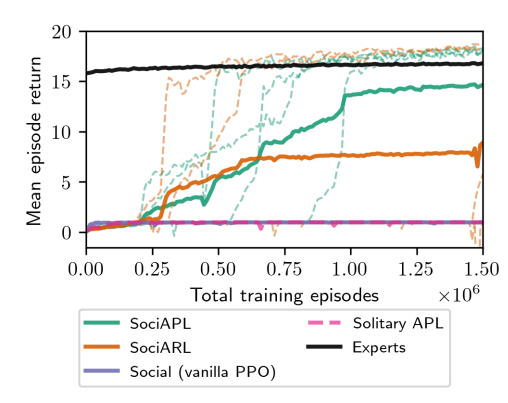
- Learning from sub-optimal experts
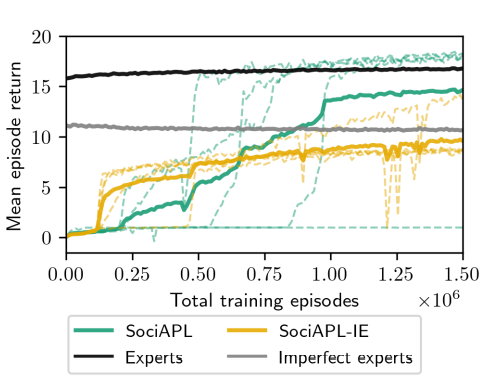
Transfer Learning on other environments
- 4 - Goal Cycle Environment
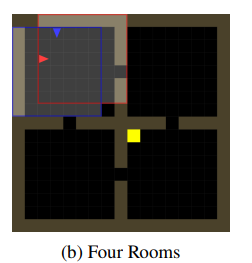
- 4 Rooms
- Reach to the goal in a limited time
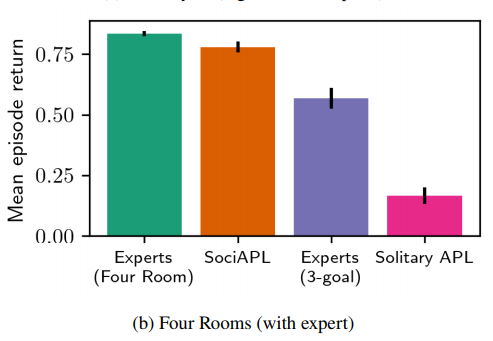
Discussion
- Training in presence of different expert agents following different strategies
- Model Based - Model - Free trade off
Too many cooks: Bayesian inference for coordinating multi-agent collaboration
Rose E. Wang, Sarah A. Wu, James A. Evans, Joshua B. Tenenbaum, David C. Parkes, Max Kleiman-Weiner
Main Contributions
- Introducing a new approach for decentralized multi-agent coordination
- This approach can train agents that can coordinate in three distinct scenarios
- Divide and conquer: agents should work in parallel when sub-tasks can be efficiently carried out individually
- Cooperation: agents should work together on the same sub-task when most efficient or necessary
- Spatio-temporal movement: agents should avoid getting in each other’s way at any time
- The approach allows agents to predict the intentions of other agents
Difference from Previous Works
- Previous works attempting to do similar things require pre-training
- Prior work often limited to action limitation
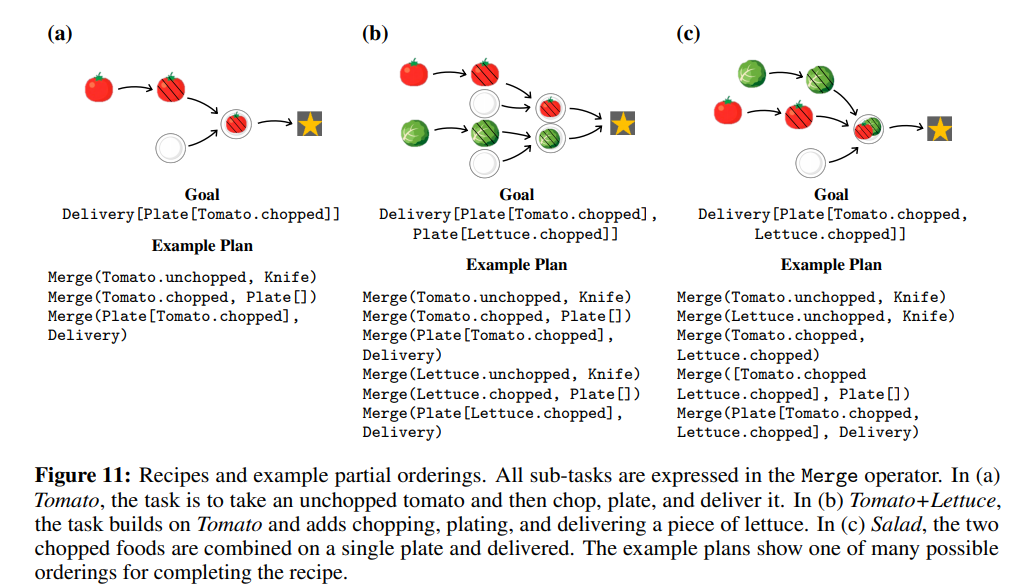
Task Description
- Environment used : Overcooked
- Multi-agent MDPs :
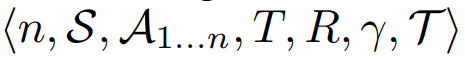
- Tasks form and ordered set, (hierarchical structure)
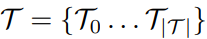
- Each task has a pre-condition that needs to be satisfied for the task to be relevant at a given point in time
- Effect of partial ordering - Multiple possible ways of allocating agents to the subtasks
- Each task can be represented as $Merge(X, Y)$
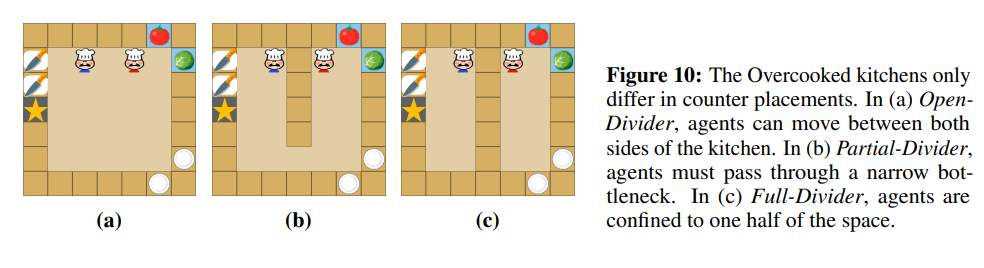
Environments
- Goal: Cook a recipe in the shortest time possible
- Kitchen Configurations:
- Tasks
Method
-
Based on Bayesian Theory of Mind
-
Approach is called Bayesian Delegation
-
Makes probabilistic inferences (beliefs -theory of mind) about the sub-tasks other agents are working on
-
$\textbf{ta}$ - Set of all possible task allocation permutations. For eg. in case of two agents
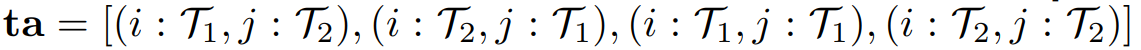
-
This posterior over the permutations is updated after every time step and then used for further planning.
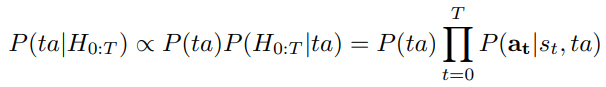
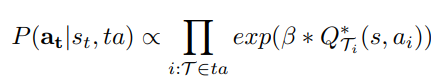
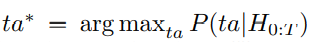
- $Q_{\mathcal{T_i}}^* (s, a_i)$ - Expected future reward of a towards completion of task $\mathcal{T_i}$ for agent $i$
- $\beta$ → degree to which the agent believes that others are acting optimally
Deciding the prior $P(ta)$
- 0 for all the $ta$s having sub-tasks without satisfied pre-conditions
- For other $ta$ :
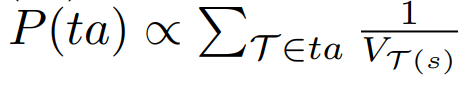
- $V_{\mathcal{T}(s)}$ - estimated value of the current state under sub-task $\mathcal{T}$
Planning
-
MBRL based planning
-
Use of Bounded Real Time Dynamic Programming (BRTDP) extended in multi-agent settings for estimating optimal Q values and policies
-
Two scenarios :
-
Agent working on a task individually ($\mathcal{T_i} \neq \mathcal{T_-i})$
-
Models rest of the agents assuming them to be stationary (level-0 models)
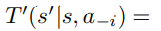
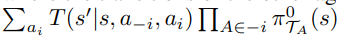
-
-
Agent working on a task along with other agent(s)
- Simulates a fictitious centralized planner which. Joint policies can then be found using single-agent policies using single-agent planners such as BRTDP
- Agent $i$ then takes the action assigned to it under joint policies
Results
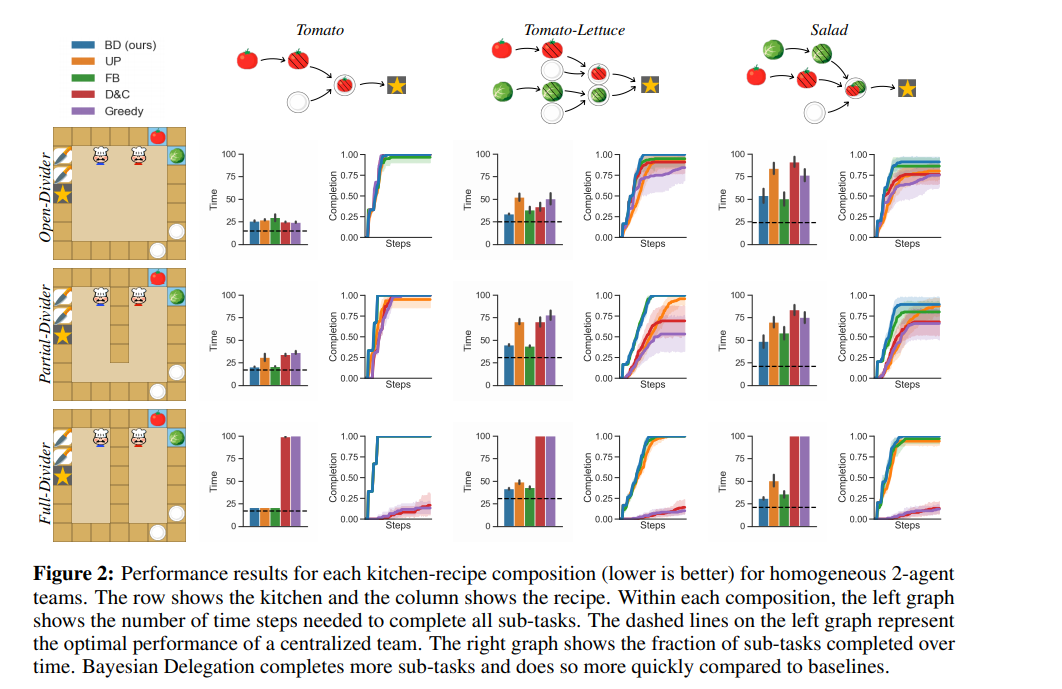
- Baselines :
- UP - Uniform priors
- FB - Fixed Beliefs
- D&C - Divide and conquer
- Greedy
- BD performs well even in ad-hoc heterogeneous scenarios (having agents following different strategies
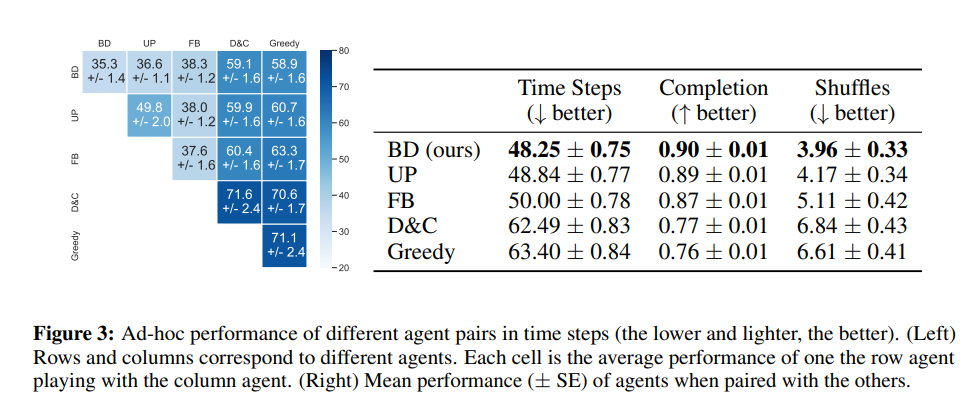
Discussion
- What if the number of agents exceed the number of sub-tasks?
-