NeurIPS2020
NeurIPS-2020
Why self-supervised learning or learning from extra data?
- Huge amount of raw image and video data available
- Ability to cover wider domains and information
Initial work focused on Pretext or Proxy tasks. Recent works have shifted to contrastive learning.
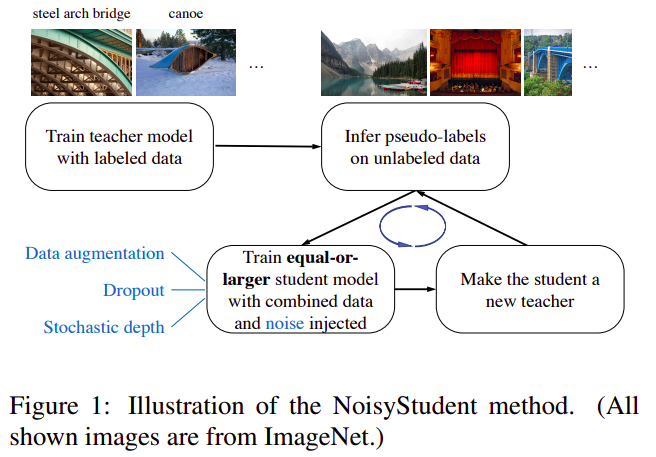
Self-training with Noisy Student improves ImageNet classification
Qizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le

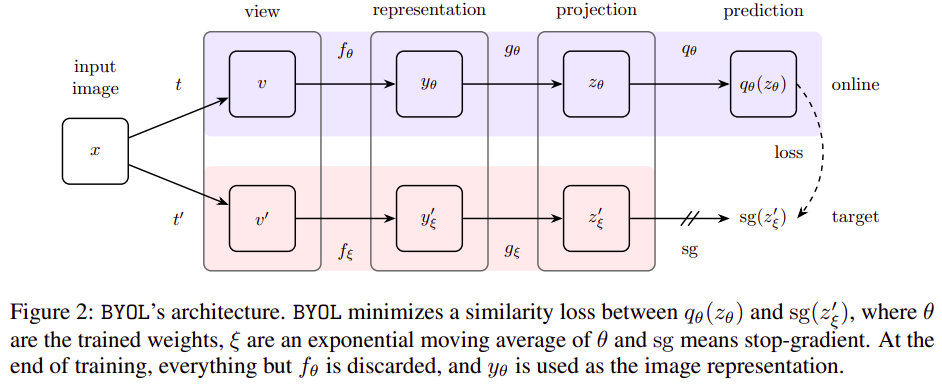
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko
Objective:
Moving away from negative samples in contrastive learning
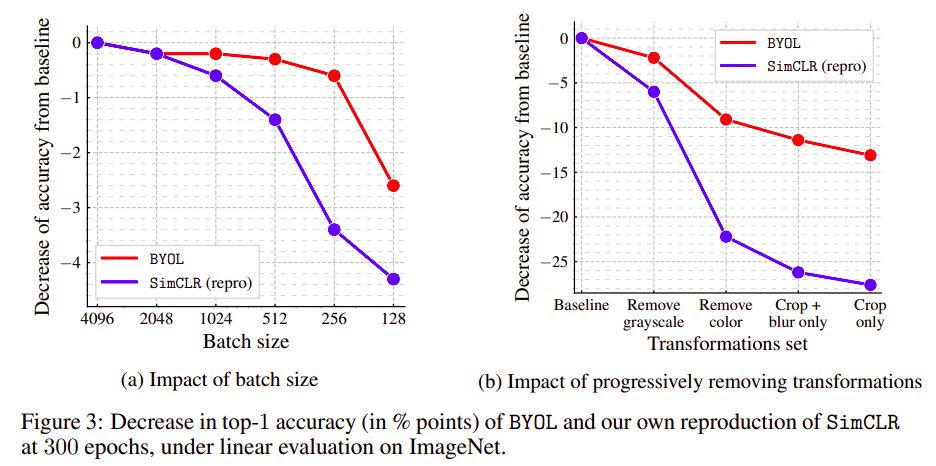
Big Self-Supervised Models are Strong Semi-Supervised Learners
Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, Geoffrey Hinton
Contributions and findings:
- Bigger Models Are More Label-Efficient
- Bigger/Deeper Projection Heads Improve Representation Learning
- Distillation Using Unlabeled Data Improves Semi-Supervised Learning
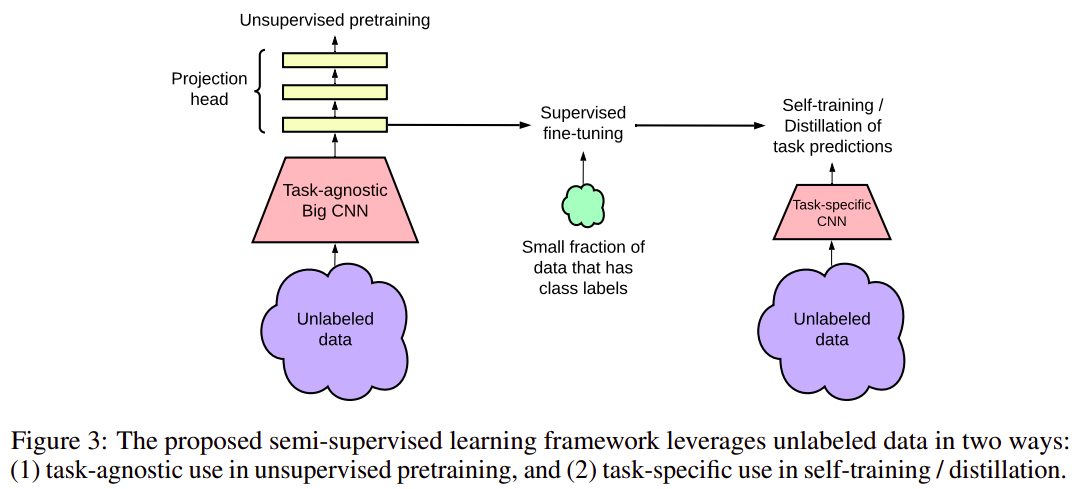
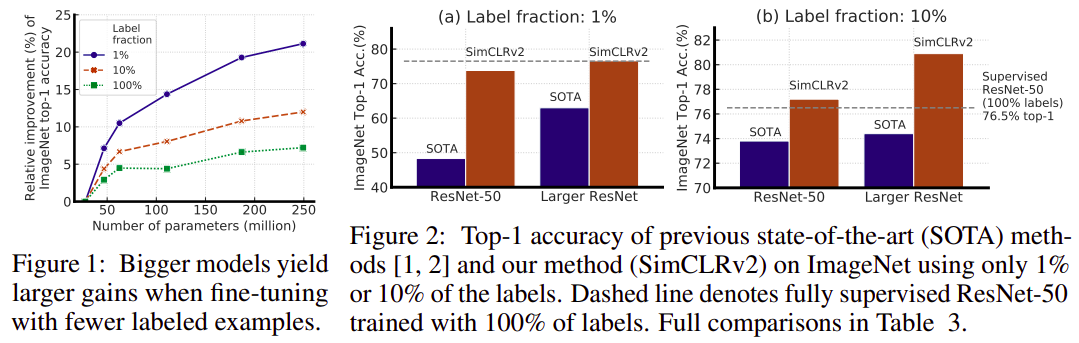
Rethinking Pre-training and Self-training
Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin D. Cubuk, Quoc V. Le
- Stronger data augmentation and more labeled data further diminish the value of pre-training
- Unlike pre-training, self-training is always helpful when using stronger data augmentation, in both low-data and high-data regimes, and
- In the case that pre-training is helpful, self-training improves upon pre-training.
For example, on the COCO object detection dataset, pre-training benefits when we use one fifth of the labeled data, and hurts accuracy when we use all labeled data. Self-training, on the other hand, shows positive improvements from +1.3 to +3.4AP across all dataset sizes.
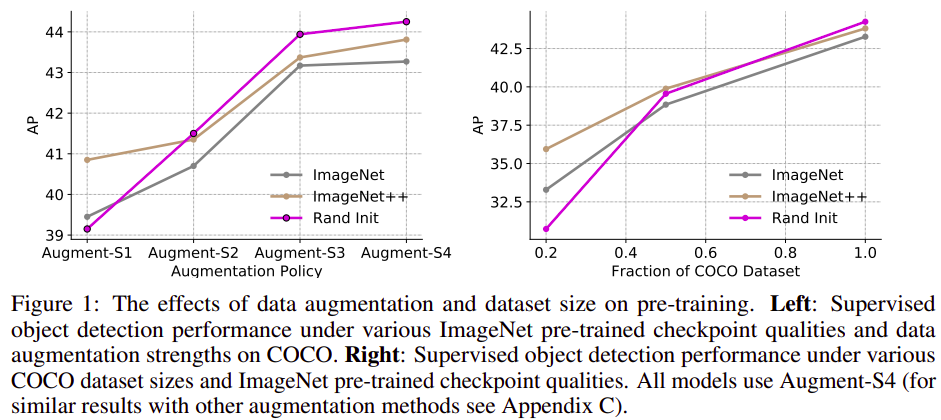
Self-training helps in high data/strong augmentation regimes, even when pre-training hurts

Self-training works across dataset sizes and is additive to pre-training.
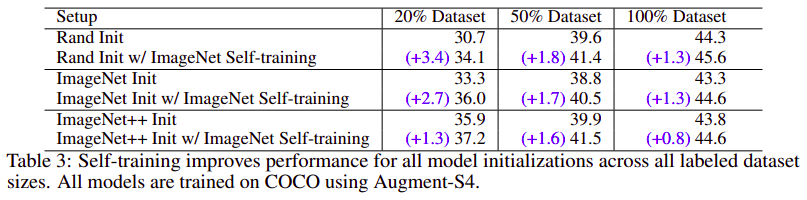
Self-supervised pre-training also hurts when self-training helps in high data/strong augmentation regimes
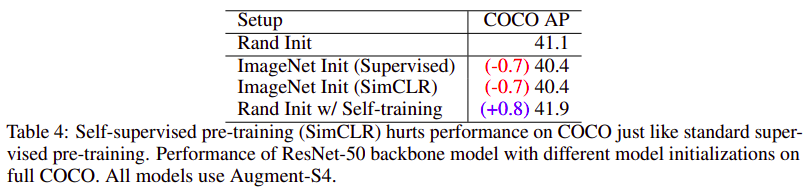
An intuition for the weak performance of pre-training is that pre-training is not aware of the task of interest and can fail to adapt. Such adaptation is often needed when switching tasks because, for example, good features for ImageNet may discard positional information which is needed for COCO.
Conclusion:
- Self-training works well in every setup that we tried: low data regime, high data regime, weak data augmentation, and strong data augmentation.
- Self-training also is effective with different architectures (ResNet, EfficientNet, SpineNet, FPN, NAS-FPN), data sources (ImageNet, OID, PASCAL, COCO) and tasks (Object Detection, Segmentation).
- Secondly, in terms of generality, self-training works well even when pre-training fails but also when pre-training succeeds. In terms of scalability, self-training proves to perform well as we have more labeled data and better models.
Self-supervised learning through the eyes of a child
A. Emin Orhan, Vaibhav V. Gupta, Brenden M. Lake
SKYCam video dataset collected by mounting cameras on children as they are growing.
3 SSL techniques:
- Temporal Classification:
- Static-Contrastive learning - Momentum contrast
- Temporal-Contrastive learning- Adjacent frames are positive
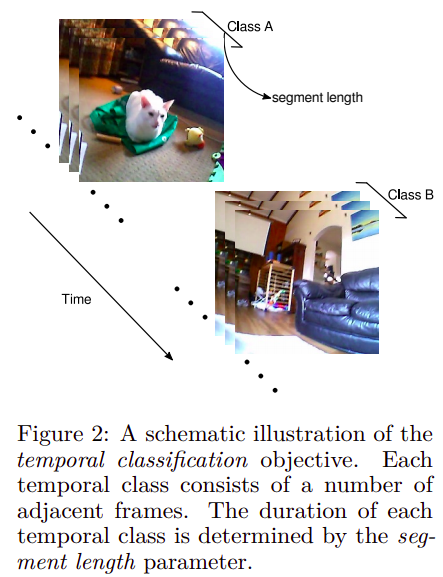
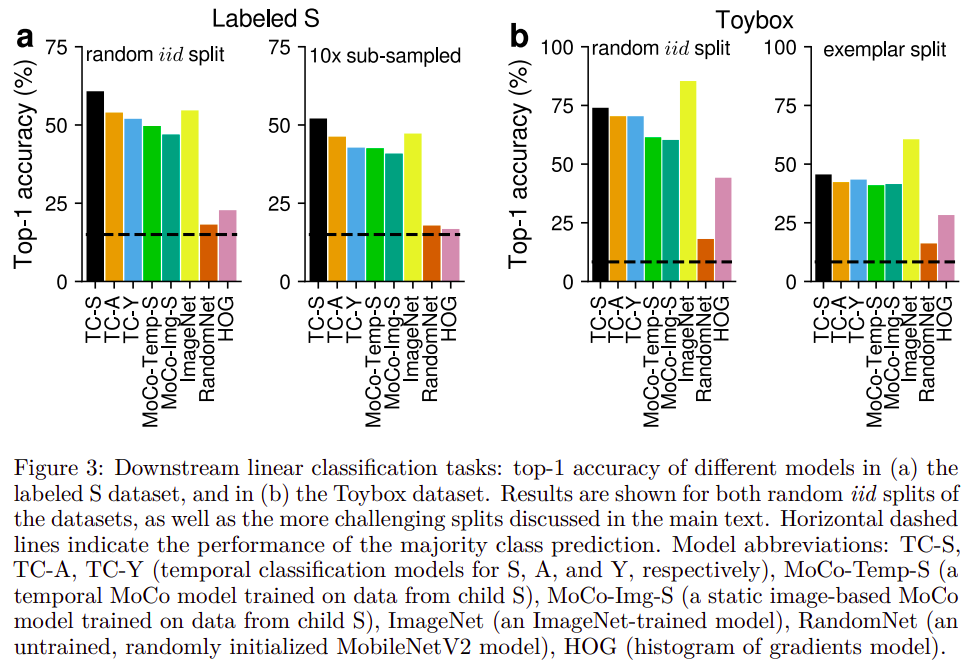
Learning from contextual cues as well since the activation maps are larger:

Limitations:
- Dataset limitation to ~1 week of learning of a child due to frequency
- No multi-modal learning or multi-sensory inputs to learn
- Self Supervised algos use unrealistic augmentations to learn. An attempt to more intuitive self-supervised learning can be moving away from such hand-crafted or thought out augmentations.